tech
storm
industry
storm 0.9.0.1版 简析
- 2014-01-23
- Chaos
今天终于有空闲时间了,赶紧把Storm环境的搭建流程以及项目部署mark一下以备忘。
Storm是啥?
Storm 是Twitter开源出来的一个分布式实时数据流处理系统。Storm使得处理“源源不停的”流式数据变得容易、可靠而有保障(吹吧)。
与Hadoop的批量处理数据相比,Storm更倾向于RealTime(实时性)的数据处理。
Storm本身是用based on JVM的函数式语言Clojure开发的。 函数式语言由于其特性天生支持并发和模块化,所以个人感觉写这种分布式、并行处理的程序十分合适。而且, 虽然Storm是跑在JVM上的,但是Storm本身依赖了Thrift 数据接口,因此我们可以用任何语言实现其接口。
我们为什么需要Storm? 难道现有的Hadoop生态系统(HDFS-HIVE-HBASE-MAPREDUCE-PIG)不能满足我们的要求?考虑如下几个应用场景: 实时性数据分析,在线机器学习算法(比如很多的增量算法),连续型计算, 分布式RPC,
ETL等。 Hadoop, hive 能满足我们离线或者异步处理一天, 或几个小时前数据的业务需求, 但如果我们需要对实时过来的新数据做出迅速处理,现有的Hadoop往往捉襟见肘。因此在这种情况下,诸如Storm这样的实时计算系统应运而生。
小Tip: 与Storm同类型的框架还有Spark+Shark 这对好基友组合。 有人在邮件列表里说Spark比storm轻量,而且易上手。也支持stream处理。除了支持流计算之外,还可以同Hadoop整合,之上的Shark(类似于Hive之于Hadoop)又能使用类SQL语法访问数据,做批处理分析,并且是内存计算,比Hive的MapReduce模型要快不少。而且Spark之上也有专门的ML库,可以用,对于在大型数据上运行各种挖掘算法很有优势,同样比Mahout要快许多。
我只能呵呵。Bite me if you can~
为什么用最新版?
Storm 0.9.0.1 是Storm项目组在2013年12月新推出的版本。与老版本相比,最大的不同在于终于可以不仅仅使用ZeroMQ作为底层数据通讯的方式了。
在之前的版本中, Storm是默认使用0mq进行底层数据传输,然而由于Storm的源码是clojure写的,实际部署的时候也往往在based on jvm的环境当中。而ZeroMQ是基于C++的, jvm对其的内存使用等并不可控, 因此在实际使用过程中总是会出现莫名其妙(诸如丢数据包)等问题。而且ZeroMQ对平台的依赖性较高,增加了搭建环境的成本。当然我并不是说ZeroMQ就不好,只是在这个实际的场景下个人觉得并不合适。
在最新版中,Storm允许你使用netty transport作为纯Java方案来替代0mq的数据通信方案。这样可以消除关于ZeroMQ的依赖。由于netty是基于Java的, 因此整个数据传输显得更好掌控。关于它的一些配置将在随后的篇幅中说明。
其它的一些改进有: 可以更好地在UI中查看工作日志(logviewer), 以及安全性的提高等。在初始阶段就不细说了。
Talk is not cheap.
现在我们就来一步一步地领略Storm的搭建流程。
首先, 推荐几个比较好的学习资源:
- Storm-cn中文邮件组
- storm Tutorial
- storm official website
- storm开源项目组中国唯一commiter 徐明明老师的Blog (用sinaapp何弃疗)
- 量子恒道关于Storm的版面文章 (里面有一些入门文章和讲述了淘宝一些具体使用Storm的应用场景)
- 我的Blog (bite me if you can~~)
还有就是Storm的官方邮件组换地儿了(>_<) ,我没找到在哪。。。
Storm的IRC也常年冷清,与Haskell的IRC没法比。
然后说正事儿。
讲配置之前,得先讲讲Storm的内部组件的构成原理,然后慢慢穿插地来。理解Storm的时候,你可以和Hadoop对比着看,虽然一个是实时的一个是批处理的,但是其组成和架构却有其相似性。比方说,在Hadoop中,你经常会去跑job, 而与之对应,在Storm中,我们把类似功能的组件叫Topologies(你可以理解为一个拓扑模型,实际上最后Storm集群架设好后就是一个由各种分工不同的节点组成的拓扑图。不过,我希望大家要忘记她的中文释义,只记得Topology就好,然后在我随后的描述去感性地理解它)。 与Hadoop中的job不同的是,一个批处理总会有结束的时候,然而,由于数据流是源源不断的,所以在她开始工作后,除非你将其kill掉,她永远不会停止,直到地老天荒。
刚才说到了我们可以把Topologies理解为由很多节点构成的拓扑模型,那么,她的节点包含哪几种呢?
先上一个Storm官网上的图。
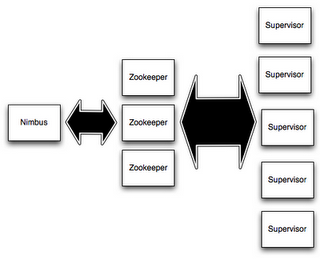
先讲讲Storm控制层面上的,而非真正业务处理逻辑上的节点。Storm控制层面上的节点有两种, Master Node和Worker Node。 Master Node 会运行一个称为”Nimbus”的守护进程(相应地,你可以想象一下Hadoop中的JobTracker), 她负责将我们写好的code, jar包 合理地分布到各个集群上, 并给各个机器分配任务, 处理机器宕机等失败情况。
相应的,Work Node则会运行一个成为”Supervisor”的守护进程。每个Supervisor会管理一个机器, 她会监听Nimbus赋予该台机器的task, 启动或停止。
那么Master Node和Work Node是如何协调起来的呢? Storms通过Zookeeper集群来将Nimbus和一个个Supervior协调管理起来。而且注意无论是Nimbus还是Supervisor都是fail-fast以及stateless的。对于这个特性你可以感性地想象一下,在Storm系统运行的过程中, 由于集群的所有状态存储在Zookeeper集群或者是本地磁盘上。因此你可以随意干掉任何一个Nimbus或者Supervisor进程,被你干掉的节点则在本地进行备份,因此可以保证其稳定性。
当然我们还是希望异常情况越少越好。不作死就不会死。
####因此,综上。想要安装Storm, 先要装Zookeeper。####
还真是麻烦啊23333
如果你已经有了一个成型的、稳定的Zookeeper集群,那就好办了。你只需要在随后的Storm配置时将你的Zookeeper的IP和端口号写进去就好了。现在我们假定你两手空空,需要先装Zookeeper。
####等等,你肯定有JDK了, 对吧?####
接着说Zookeeper。我们先从zookeeper官网下载。 然后在conf目录中将zoo_sample.cfg文件back up一份改名为zoo.cfg作为我们zookeeper的配置文件。 打开它,

其中,dataDir定义了zookeeper数据文件的目录,你可以改成你自己的目录。重点是你要在配置文件中定义 zookeeper集群节点的IP和端口号。
比如我目前只有一个节点,于是,

在后面添加server.1的IP和端口号。你可以添加多个。本文中,我只添加了本地IP一个节点。
然后,我们进入bin/目录。执行zkServer.sh start启动zookeeper

####搭建storm环境####
接下来就是搞起Storm环境的重头戏了。